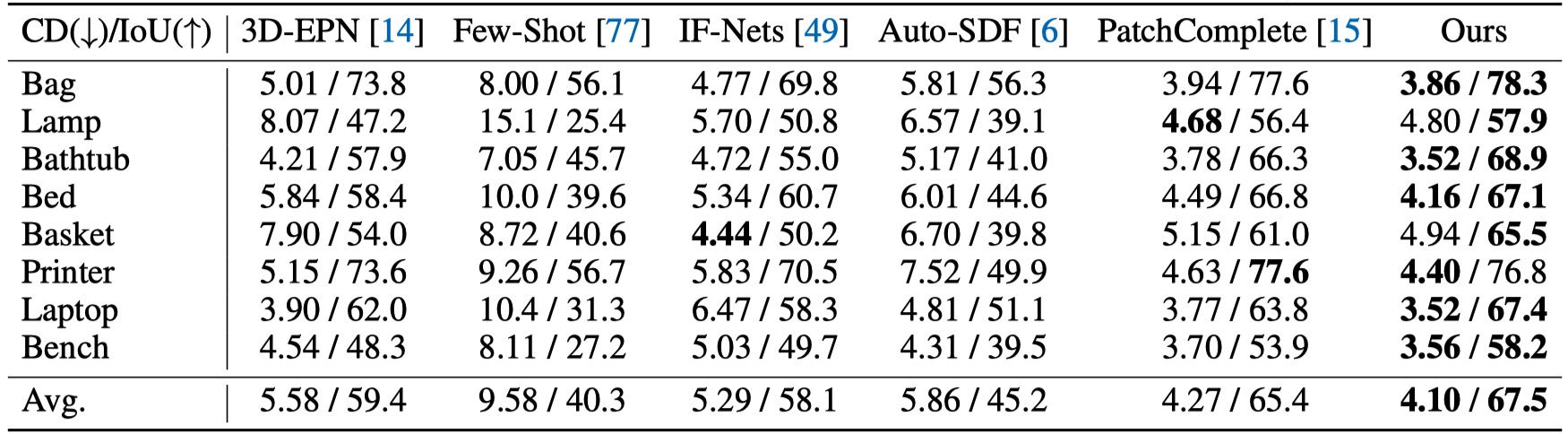
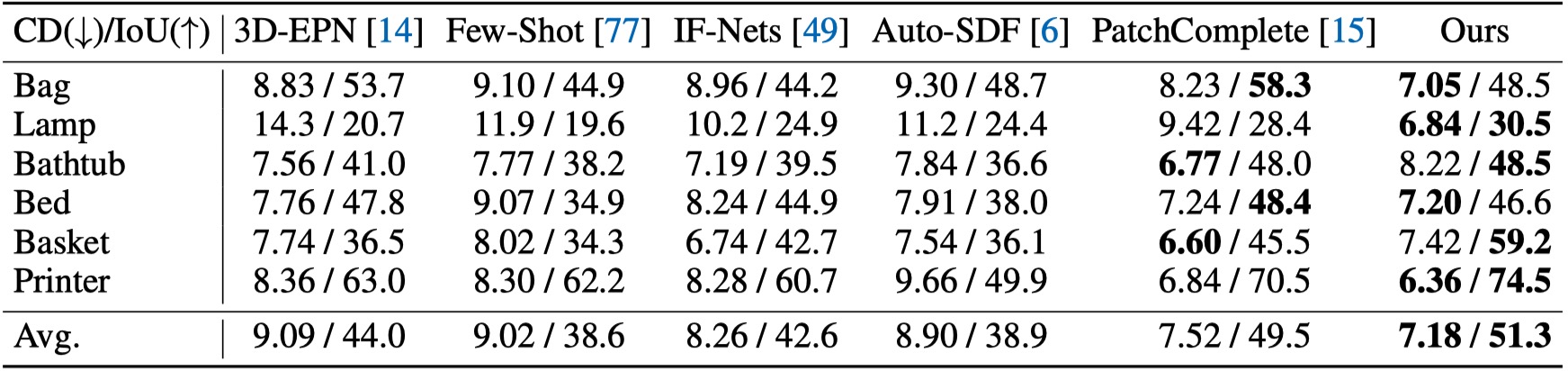
Method
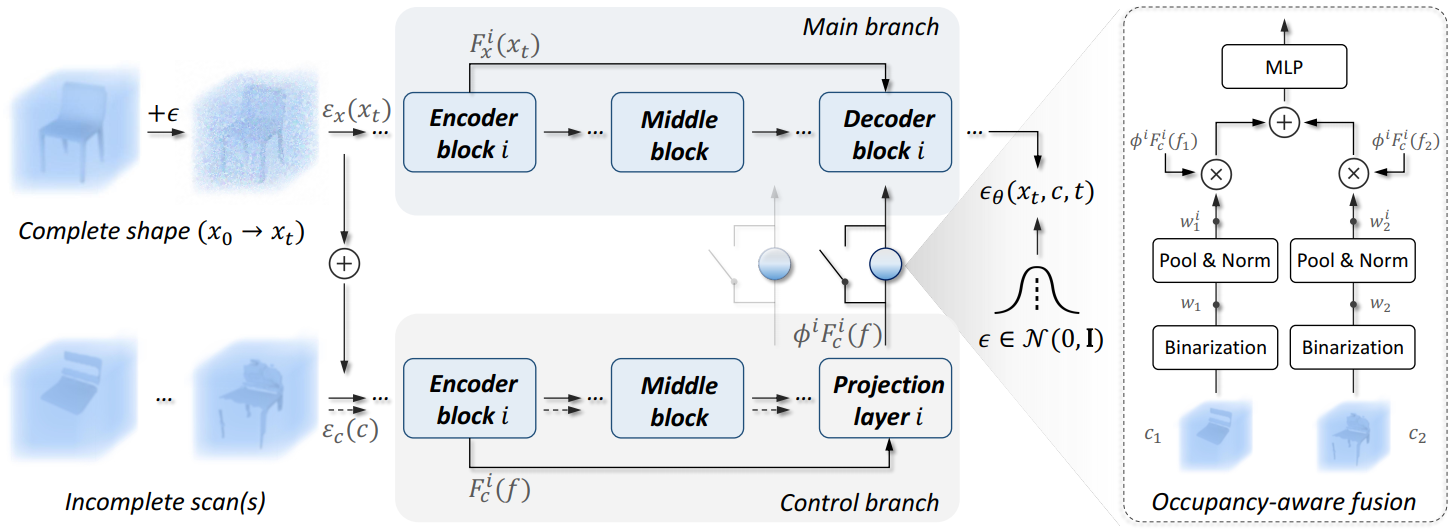
Figure 1. An overview of DiffComplete framework. Given a corrupted complete shape x_t (diffused from x_0) and an incomplete scan c, we first process them into ε_x(x_t) and ε_c(c) to align the distributions. We employ a main branch to forward ε_x(x_t), and a control branch to propagate their fused features f into deep layers. Multi-level features of f are aggregated into the main branch for hierarchical control in predicting the diffusion noise. To support multiple partial scans as condition, e.g., two scans {c_1,c_2}, we switch on occupancy-aware fusion. This strategy utilizes the occupancy masks to enable a weighted feature fusion for c_1 and c_2 by considering their geometry reliability before feeding them into the main branch.